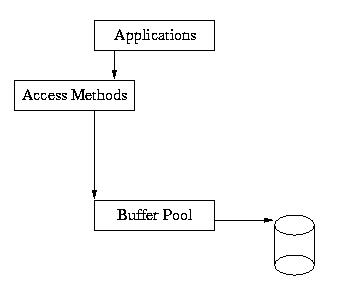
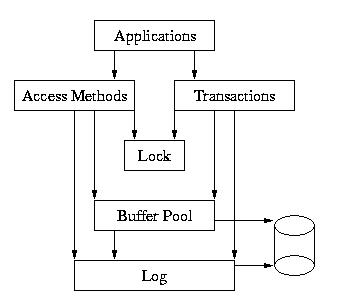
一个环境可以被很多进程和线程共享。一个环境包含其它目录的资源也是可能的。应用程序经常选择把资源分布到其他目录或磁盘来提高性能或其他原因。尽管如此,默认的,数据库,共享区(锁,日志,内存池和事务共享内存区域)和日志文件将存储在同一个同层次目录中。
意识到所有应用程序共享一个数据库环境默认的相信彼此非常重要。他们能访问对方的数据,因为那些数据在同一个共享内存区,他们也共享资源像buffer空间和锁。与此同时,任何应用程序使用同一个数据库,必须共享一个环境,如果想在他们之间保持一致性的话。
Creating a database environment
环境对于bdb的可移植性和灵活性是非常重要的。为了增强可移植性,和快速灾难恢复,建议尽量使用相对路径。建议使用配置文件放置环境参数而不要直接写到程序里,可以避免每次移植时修改和编译源文件。
bdb环境由db_env_create 和 DB_ENV->open接口创建和描述,再需要定制的地方,比如把log文件存储到不同的磁盘驱动器里,或选择一个特殊cache大小, 应用程序描述这些定制信息通过创建配置文件,或者传参数给其他DB_ENV 处理函数。
一旦一个环境被创建,被指定相对路径的数据库文件,都将相对与环境的home目录来创建。用相对目录允许整个环境轻易的移动。简化了在不同目录和不同系统中重建和恢复的步骤。
应用程序首先通过db_env_create方法获得一个环境句柄,然后调用DB_ENV->open来创建或合并数据库环境。这儿有很多选项你可以在调用DB_ENV->open时设置来定制你的环境。这些选项大致可以分为四类:
子系统初始化选项: 这些标志指明哪些bdb子系统将因为环境被初始化,和哪些操作将自动发生当数据库在环境中被访问的时候。这些标志包括DB_INIT_CDB, DB_INIT_LOCK, DB_INIT_LOG, DB_INIT_MPOOL, and DB_INIT_TXN。The DB_INIT_CDB标志为bdb并发数据存储做初始化工作。其他标志初始化单个子系统;也就是说,当DB_INIT_LOCK被指定,应用程序读写在这个环境中打开的数据库时,将使用locking子系统以确保它们不覆盖对方的对数据的改动。
恢复选项:这些包括DB_RECOVER 和 DB_RECOVER_FATAL选项,他们表明在环境被打开要作正常用途使用前,恢复(recovery)将要进行。
命名选项:这包括DB_USE_ENVIRON 和 DB_USE_ENVIRON_ROOT,修改如何在环境中给文件命名。
混杂选项:例如DB_CREATE选项使底层数据库文件被创建是必需的。更多的应用还指定
仅仅DB_INIT_MPOOL标志或者指定其它所有4个子系统的初始化标志(DB_INIT_MPOOL, DB_INIT_LOCK, DB_INIT_LOG, and DB_INIT_TXN)。
以前的配置只是想简单的用一些基本的访问方法接口用一个共享底层缓冲池,但是没有关心当应用程序或系统出现故障时的可恢复性。以后是一些需要提供可恢复性的应用。也有一些很稀少的情况下,其它的初始化标志组合成为可能。
DB_RECOVER在当应用程序想在运行的时做一些必需的数据库恢复的时候被指定。也就是说,是否在上次运行时,系统或应用程序出现了故障,想在再次运行前使数据恢复到可用状态。不过,在没有任何数据需要恢复的情况下,指定这个标志也不为错。
DB_RECOVER_FATAL标志有更特殊的用途。它执行灾难性的数据库恢复,通常需要做一些初始化的安排;也就是归档log文件被带回到文件系统。应用程序通常不指定这个标志,取而代之的是,在这种很稀有的情况下,db_recover 公用程序将会派上用场不用你自己写。
下面是一个简单的为事务程序打开一个数据库环境的例子:
DB_ENV *
db_setup(home, data_dir, errfp, progname)
char *home, *data_dir, *progname;
FILE *errfp;
{
DB_ENV *dbenv;
int ret;
/*
* Create an environment and initialize it for additional error
* reporting.
*/
if ((ret = db_env_create(&dbenv, 0)) != 0) {
fprintf(errfp, "%s: %s\n", progname, db_strerror(ret));
return (NULL);
}
dbenv->set_errfile(dbenv, errfp);
dbenv->set_errpfx(dbenv, progname);
/*
* Specify the shared memory buffer pool cachesize: 5MB.
* Databases are in a subdirectory of the environment home.
*/
if ((ret = dbenv->set_cachesize(dbenv, 0, 5 * 1024 * 1024, 0)) != 0) {
dbenv->err(dbenv, ret, "set_cachesize");
goto err;
}
if ((ret = dbenv->set_data_dir(dbenv, data_dir)) != 0) {
dbenv->err(dbenv, ret, "set_data_dir: %s", data_dir);
goto err;
}
/* Open the environment with full transactional support. */
if ((ret = dbenv->open(dbenv, home, DB_CREATE |
DB_INIT_LOG | DB_INIT_LOCK | DB_INIT_MPOOL | DB_INIT_TXN, 0)) != 0) {
dbenv->err(dbenv, ret, "environment open: %s", home);
goto err;
}
return (dbenv);
err: (void)dbenv->close(dbenv, 0);
return (NULL);
Opening databases within the environment
一旦环境被创建,数据库句柄将可能在这个环境中打开,这由db_create函数通过指定特定的环境作为参数来实现。
文件命名,数据库操作,和错误处理等都将因为这个指定的环境而被做。例如,如果DB_INIT_LOCK 或 DB_INIT_CDB 标志被指定,当环境被创建或被合并时,数据库操作将为应用程序自动的执行所有必要的锁操作。
下面是一个简单的例子,在一个环境中打开两个数据库:
DB_ENV *dbenv;
DB *dbp1, *dbp2;
int ret;
dbenv = NULL;
dbp1 = dbp2 = NULL;
/*
* Create an environment and initialize it for additional error
* reporting.
*/
if ((ret = db_env_create(&dbenv, 0)) != 0) {
fprintf(errfp, "%s: %s\n", progname, db_strerror(ret));
return (ret);
}
dbenv->set_errfile(dbenv, errfp);
dbenv->set_errpfx(dbenv, progname);
/* Open an environment with just a memory pool. */
if ((ret =
dbenv->open(dbenv, home, DB_CREATE | DB_INIT_MPOOL, 0)) != 0) {
dbenv->err(dbenv, ret, "environment open: %s", home);
goto err;
}
/* Open database #1. */
if ((ret = db_create(&dbp1, dbenv, 0)) != 0) {
dbenv->err(dbenv, ret, "database create");
goto err;
}
if ((ret = dbp1->open(dbp1,
NULL, DATABASE1, NULL, DB_BTREE, DB_CREATE, 0664)) != 0) {
dbenv->err(dbenv, ret, "DB->open: %s", DATABASE1);
goto err;
}
/* Open database #2. */
if ((ret = db_create(&dbp2, dbenv, 0)) != 0) {
dbenv->err(dbenv, ret, "database create");
goto err;
}
if ((ret = dbp2->open(dbp2,
NULL, DATABASE2, NULL, DB_HASH, DB_CREATE, 0664)) != 0) {
dbenv->err(dbenv, ret, "DB->open: %s", DATABASE2);
goto err;
}
return (0);
err: if (dbp2 != NULL)
(void)dbp2->close(dbp2, 0);
if (dbp1 != NULL)
(void)dbp2->close(dbp1, 0);
(void)dbenv->close(dbenv, 0);
return (1);
}
Error support
db_strerror能根据一个bdb的一个错误返回值返回一个指向错误信息的指针。它可以处理系统的错误返回值也能处理bdb特有的返回值。
例如:
int ret;
if ((ret = dbenv->set_cachesize(dbenv, 0, 32 * 1024, 1)) != 0) {
fprintf(stderr, "set_cachesize failed: %s\n", db_strerror(ret));
return (1);
}
这儿也有两个附加的错误处理函数:DB_ENV->err 和 DB_ENV->errx。
DB_ENV->err函数追加标准错误字符串到已构造好的信息,而DB_ENV->errx不那样。
错误信息可以通过DB_ENV->set_errpfx被配置成总包含一个固定的东西,例如,应用程序名称。还可以把错误信息输入到一个指定的文件中,例如:
int ret;
dbenv->set_errfile(dbenv, errfp);
dbenv->set_errpfx(dbenv, program_name);
if ((ret = dbenv->open(dbenv, home,
DB_CREATE | DB_INIT_LOG | DB_INIT_TXN | DB_USE_ENVIRON, 0))
!= 0) {
dbenv->err(dbenv, ret, "open: %s", home);
dbenv->errx(dbenv,"contact your system administrator:
session ID was %d",session_id);
return (1);
}
例如应用程序名为"my_app", 环境的home目录为 "/tmp/home",出错信息将是这样的:
my_app: open: /tmp/home: Permission denied.
my_app: contact your system administrator: session ID was 2
DB_CONFIG configuration file
几乎所有可以指定给DB_ENV那些方法的配置信息,也都能通过一个配置文件来指定。如果一被命名为DB_CONFIG的文件存在于数据库hone目录下,它将会一行行的按NAME VALUE的格式读入。
NAME和VALUE之间用一个或者多个空格来分割。凡是那一行的开头是空格或#的,都将被忽略为注释。
NAME VALUE具体值可以在对用的方法中查到例如DB_ENV->set_data_dir。
DB_CONFIG配置文件的目的是允许管理员定制不依赖于应用程序的环境。例如,可以移动数据库log文件和数据文件到不同的地方,而不用重新编译应用程序。另外,因为DB_CONFIG文件是当数据库环境被打开时读取的,它可以用来覆盖在那以前配置的规则。例如,可以定义一个更合理的cache大小,来覆盖以前已经编译到程序中的值。
File naming
下面介绍几种可能的为bdb指定文件命名信息的方法。
db_home: 为DB_ENV->open的
db_home参数指定一个非NULL值,它的值将会用来作为数据库的home,以后的文件命名都是相对这个路径的。
DB_HOME:为环境变量
DB_HOME指定值,DB_ENV->open被调用时候,读取这个值,把它作为数据库home,以后的文件命名都是相对这个路径的。
DB_ENV方法:这有三个方法可以影响文件命名。DB_ENV->set_data_dir可以为数据库文件指定一个目录。DB_ENV->set_lg_dir方法可以为log文件指定目录。DB_ENV->set_tmp_dir为创建的临时文件指定一个目录。例如,一个应用程序可以将数据文件,日志文件等分别放在不同的目录下。
DB_CONFIG文件:相同的指定给DB_ENV 方法的信息,也可以用DB_CONFIG 配置文件来指定。
我觉得指定的优先级从高到低应该是这样的:DB_ENV,DB_CONFIG,db_home,DB_HOME,default。如果以上的值为绝对路径,那么home就是那个绝对路径。如果以上的值为相对路径,那么将根据当前的工作目录算出home路径。如果什么都没指定,那么默认的是现在的工作目录为home。
例子:
情况一:把所有的文件都放在目录/a/database下:
dbenv->open(dbenv, "/a/database", flags, mode);
情况二:把临时文件放在/b/temporary,把所有其他文件放在/a/database:
dbenv->set_tmp_dir(dbenv, "/b/temporary");
dbenv->open(dbenv, "/a/database", flags, mode);
情况三:把数据文件放在/a/database/datadir,日志文件放在/a/database/logdir所有其他文件放在/a/database:
dbenv->set_lg_dir(dbenv, "logdir");
dbenv->set_data_dir(dbenv, "datadir");
dbenv->open(dbenv, "/a/database", flags, mode);
情况四:
把数据文件放在/a/database/data1和/b/data2,所有其他文件放在/a/database.
任何数据文件将被创建在/b/data2目录下,因为它是第一个被指定的数据目录:
dbenv->set_data_dir(dbenv, "/b/data2");
dbenv->set_data_dir(dbenv, "data1");
dbenv->open(dbenv, "/a/database", flags, mode);
。。。。。
Shared memory regions
每个在环境中的bdb子系统都被一个或多个区域(regions),或大块的内存来描述。区域包括所有的每进程和每线程共享信息,(包括互斥)
,这些组成了bdb环境。这些区域将下列在三种内存类型中的一种中被创建,这取决于指定给DB_ENV->open方法的标志:
DB_PRIVATE:如果这个标志被指定,区域将在每进程的堆内存中被创建;也就是说由malloc()返回的内存。
这个标志最好不要指定当一个以上的内存访问环境的时候。因为它很有可能引起数据库腐烂(corruption)和一些不可预知的行为,例如,当
server应用程序和bdb公用程序,(例如:db_archive, db_checkpoint or db_stat)都有可能访问这个环境的时候,B_PRIVATE标志最好别指
定。
DB_SYSTEM_MEM:如果这个标志被指定,共享区域将在系统内存中创建而不是在文件中。这是一个可选的机制,为了在多个进程和一个进程中的
多线程间共享bdb环境。bdb所使用的系统内存潜在地很有用,陪任何特殊的进程度过一生。因此附加的清除将是必要的当一个应用程序出现故
障后,因为bdb没有办法去确认,支撑共享内存区的系统资源是不是还给了系统。
系统内存的使用是根据计算机体系结构而定的。例如,在一个支持 X/Open样式共享内存的系统上,像UNIX系统,shmget(2) 和相近的
系统V IPC接口被使用。在VxWorks 系统中使用系统内存。在这些情况下,一个初始的段id必须在应用程序中被指定,以确保应用程序不互相覆
盖对方的数据库环境。因此,段创建的数量不是无限制的增长。可以参考DB_ENV->set_shm_key方法得到跟多的信息。
在windows平台上DB_SYSTEM_MEM标志问题多多,我就不说了.
default:如果没有内存相关的标志被指定给DB_ENV->open,被文件系统支撑的内存(觉得应该可以理解为虚拟内存)将用来存储这区域(regions)。在unix系统上,bdb库将将使用POSIX mmap接口。如果mmap不可用,那么unix shmget接口将可能被使用,如果它可用的话。
任何在文件系统中创建用来支撑区域的文件,将在环境的home目录下被创建。这些文件命名为__db.###(例如,_db.001, __db.002等等)。
当区域文件被文件系统来支撑的时候,每个区域对应一个文件被创建。当区域文件被系统内存来支撑的时候,只有一个文件将仍然被创建,因为这儿必须有一个熟知的名字在文件系统中,以便多进程能定位到环境所使用的系统共享内存。
统计在环境中的共享内存区域可以用db_stat的-e选项来显示。
Security
下面是当你在写bdb应用程序的时候需要考虑的安全问题:
数据库环境许可:
被bdb数据库环境使用的目录,应该有它自己的许可设置,以确保那些没有适当权限的用户不能访问环境里的文件。应用程序,那些添加到用户
的许可(例如,unix的setuid 或 setgid程序), 应该细心的检查,不允许违法的使用这些许可,例如访问在环境中的文件。
环境变量:
设置 DB_USE_ENVIRON 和 DB_USE_ENVIRON_ROOT标志 和允许在文件命名时使用环境变量都是危险的。在bdb应用程序中用附加的许可(例如,
unix的setuid 或 setgid程序)设置这些标志,将潜在地允许那些正常情况下没有权限的用户读写数据库。
文件许可:
默认地,bdb总是创建所有者和所在组可读写的文件(也就是,S_IRUSR, S_IWUSR, S_IRGRP 和 S_IWGRP; 或八进制模式 0660 在历史性的UNIX
系统上),创建文件的组的所有权,是基于系统和目录默认的,不被bdb进一步的指定。
临时支撑(backing)文件:
如果一个没有被命名的数据库被创建,而cache太小以至于不能在内存中控制这个数据库,bdb将创建一个临时的物理文件使它能把数据库的cache页放到磁盘上,当需要的时候。
在这种情况下,环境变量,像TMPDIR可能被用来指定用以定位那个临时文件。尽管临时支撑文件被创建被只有所有者可读写的。(S_IRUSR 和 S_IWUSR, 或八进制模式 0660 在历史性的UNIX系统上),一些文件系统可能不能充分的保护被创建在随机目录中的临时文件。为了绝对安全,应用程序存储敏感数据在未命名的数据库中,应该用DB_ENV->set_tmp_dir方法用已知的许可(known permissions)指定一个临时目录。
Encryption
bdb可选择的用Rijndael/AES算法支持加密和解密。这个加密只是文件级的,如果侵入者能够访问你系统的内存,那么这种加密就不能提供保障
了。与我的应用无关我就不多说了。自己看手册。
Remote filesystems
最好别使用远程文件系统,像nfs等。因为区域文件要映射到内存,远程文件系统不能很好的支持某些语义。数据库文件,的日志文件,临时文
件,还勉强可以放在远程文件系统上,如果远程文件系统完全支持标准POSIX文件系统语义的话。总之,不用最好。
Environment FAQ
我使用多进程访问bdb数据库环境,这儿有什么方法可以确保两个进程不同时执行数据恢复(recovery )操作吗?或者说,确保其他所有的进程都退出了,可以运行数据恢复了?
其实重点要说明的是,当执行数据恢复的时候要确保没有别的进程在使用这个环境。
很多应用程序组,写一个小的监视程序,来恢复数据库环境,然后执行那些实际上用数据库环境工作的进程。监视程序然后监视工作的进程,如果任何工作进程发生故障推出或其他原因,监视程序将kill所有仍然存活的其他进程,然后执行恢复任务,然后重新这个循环。
前面漏掉的一些东东。
腐烂数据的处理或者说数据库文件的瘦身:
当你从Btree或Hash数据库删除key/data对时,它并不把这个返回给文件系统,这使得数据重用成为可能。也就是说Btree和Hash数据库都是只增的。当你删除大量key/data对时,你可能想使数据库文件也缩减,你应该建立一个新的数据库文件,把记录从旧文件复制过去。应该是导入导出记录,而不是直接copy文件。
字节序的问题:
例如:数字254~257。在一个小数在前(little-endian)的系统上是:
254 fe 0 0 0
255 ff 0 0 0
256 0 1 0 0
257 1 1 0 0
如果你把他们当成字符串处理那么他们的排序是糟糕的:
256
257
254
255
在一个大数在前(big-endian)系统上是:
254 0 0 0 fe
255 0 0 0 ff
256 0 0 1 0
257 0 0 1 1
and so, if you treat them as strings they sort nicely. Which means, if you use steadily increasing integers as keys on a big-endian system Berkeley DB behaves well and you get compact trees, but on a little-endian system Berkeley DB produces much less compact trees. To avoid this problem, you may want to convert the keys to flat text or big-endian representations, or provide your own Btree comparison function.
Introduction
bdb包括对构建基于复制(replication)的高可用性应用程序的支持。bdb replication组由一些独立配置的数据库环境组成。
组里只有一个master数据库环境和一个或多个client环境。Master环境支持读和写,client环境支持只读。如果master环境倒掉了,应用程序将可能提升一个client为新的master。数据库环境可能在单独的计算机上,在单独的硬件分区上(partitions)一个不统一的内存访问系统上,或在一个单独的server的一个磁盘上。唯一的约束就是,replication组的所有的参与者必须在一个字节序(endianness)相同的机器上(都是大数再前或都是小数在前的操作系统)。我们期望这个约束在以后的版本中会去掉。因为总是用bdb环境,任何数量的并发进程或线程可能访问一个数据库环境。在master环境中,多个线程可能读写这个环境。在client环境中,多个线程可能要读这个环境。
应用程序可能被编写成在master和clients间提供不同程度的稳固性。系统能同步的运行以便复制品(replicas)能保证是最新的,对应于所有已提交的事务。但是这样做可能回招致性能上的很大的下降。高性能解决方案有考虑全局的稳固性,允许clients的数据过时一个应用程序可控制的一段时间。
尽管bdb包括必要的构建高可用性数据库环境的底层基础,应用程序仍然必须提供一些鉴定的(critical)组成部分:
应用程序有责任提供通信下部构造。应用程序可能用任何适当的通信协议。例如RPC, TCP/IP, UDP, VI或底板(backplane)消息传递。
应用程序有责任命名。bdb涉及到一个replication组成员的时候是靠一个应用程序提供的id,应用程序必须映射那个id到一个特殊的数据库环境中或通信通道中。
应用程序有责任监视master和clients的状态,和识别任何不可用的(unavailable)数据库环境。应用程序必须提供所有的需要的安全策略。
例如,应用程序可能选择去加密数据,用一个安全的套接层,或什么也不做。
最后,bdb replication实现还有一个附加的特性去增强可靠性。bdb中的replication实现成执行数据库更新用一个不同的编码路径而不是用标
准的。这意味着,有bug的软件的操作可能会毁坏replication master,但不会把clients也毁坏。
Replication和相近的方法的描述:
DB_ENV->rep_elect 举行一个replication竞选
DB_ENV->rep_process_message 处理一个replication消息
DB_ENV->rep_stat Replication统计
DB_ENV->rep_sync Replication同步
Replication 配置:
DB_ENV->rep_set_config 配置replication系统
DB_ENV->rep_start 为replication配置一个环境
DB_ENV->set_rep_limit 限制在响应但个消息时的数据发送
DB_ENV->set_rep_transport 配置replication传输
Replication environment IDs
每个在replication组中的数据库环境必须有一个独一无二的标识符,为它自己和其它replication组中的成员都分配一个不同标识符。这些标识符不必要是全局的,也就是说,每个数据库环境可以分配本地化的标识符给replication组的成员。就是在每数据库环境中都能区分出其他成员就行了,当然全局统一给指定标识符也不为错,只是非必要的。
应用程序有责任去标志每个进来的传递给DB_ENV->rep_process_message的有适当标识符的replication消息。随后,bdb将用这些相同的标识符去标志发送函数发出去的消息。
负标识符被bdb保留使用,不应该被应用程序指定给那些环境。有两个保留的标识符准备给应用程序使用的是:
DB_EID_BROADCAST:指定一个消息应该被广播给所有replication组中的成员。
DB_EID_INVALID:是一个无效的环境id,可能被用于初始化一些环境id变量,那些变量随后被检查合法性。
Replication environment priorities
每个replication组中的数据库环境变量必须有一个优先权,它指定了在replication组中不同环境间的一个相对的顺序。这个顺序在币桓鰉aster倒掉,在决定选举哪个环境作为新master的时候的一个重要因素。优先权必须是一个非负的整数,但不必要replication组中是独一无