1. 引言
在制作电影《泰坦尼克号》所用的160台Alpha图形工作站中,有105台运行的是Linux操作系统,这160台Alpha工作站是做图形处理。图形处理中有一项重要的任务—计算。这些计算机是被利用群集技术(Cluster)组织到一起的。这就是cluster中的一种—“并行计算”。
2. Cluster概况
Cluster只是一个笼统的概念,刚才提到的“并行计算”只是cluster的一个方面,这方面的主要应用就是用低成本的“低档”电脑去做super computer的工作。
Cluster分为下面几方面
l 高可用性,High-Availability (HA)
l 负载平衡,Load Balance
l 科学计算,即并行计算,Scientific Computing
1. HA:用在不允许中断服务的场合。实际上是两台(或更多台)计算机通过一定方式互相监听,实现热备份。当其中的主服务器(primary server)出现问题时,备份服务器(standby backup server or secondary server)能够自动立即接替工作,使用户感觉不出停机。在primary server恢复正常之后,backup server又会把工作还给primary server。
2. Load Balance:在web server上的应用比较多(尽管它支持很多别的协议如ftp, telnet, sendmail等,但用处最多的还是http服务)。用户访问一个地址,但实际上后台是有若干台服务器在提供服务。而当服务请求达到饱和时,还可以很容易地再添加新的节点而不用停掉整个cluster,实现所谓的“热插拔”,这也就是Cluster中的一个概念—Scalability (易扩展性)。而且,cluster还会查询真实节点的情况,当某台真实节点没有响应时,就不再把任务分配到那里,直到这台节点恢复正常。
3. Scientific,主要用于计算量大的场合。比如刚才提到的图象处理,或一些海量计算的科学实验,以及国防应用。
那么什么是cluster呢?
1.Clustering是用两个(或更多)的系统(节点)在一起工作,来提供相同服务或实现相同目的;
2.在外面看来,整个体系结构象一个完整的系统;
3.Clustering用来提高服务的稳定性和/或核心网络服务的性能。
2.1 HA (heartbeat)
在HA方面,heartbeat(心跳)是代表技术。Heartbeat的工作方式属于Server Monitor(服务器监控)方式,即备份服务器和主服务器互相监听的一种技术。这种方式的特点是
l 提供了可用性(availability),但没有提供可扩展性(Scalability)。
l 只限两台节点
l 两台节点执行相同的服务,但只有主节点与外界通讯
l 当主节点出问题时,备份节点马上接替工作
Server Mirror解决方案的例子有:
Novel SFT III
Vinca Standby Server
Compaq Standby Server
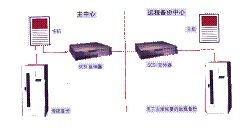
下图为Compaq Standby Server的应用示例:
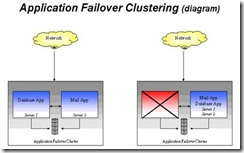
还有另外两种方式—Application Failover,Fault Tolerant
l 应用程序故障接管技术(Application Failover)
采用这种方式的例子有:
Microsoft Cluster Server
Digital Clusters
Sun Clusters
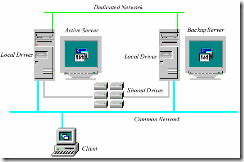
下图为Microsoft Cluster Server的一种配置示例:
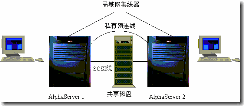
下图为Digital Clusters的一种配置示例
l 容错技术(Fault Tolerant)
这种技术的优点也很多,特别是可以作到不间断客户端的连接就可以接替服务,但价格较贵,一般都在$1,000,000以上。
代表产品有:
Tandem (Compaq) NonStop Cluster
前几届的师兄们所做的广东省自然科学基金项目:基于Unix容错技术的研究,就属于这方面的范畴。
2.2 Load Balance(LVS, TurboCluster)
负载均衡的群集技术主要应用于Web服务器群中,解决Web服务器在高访问量时的负载分流问题。
下面是一种成熟的商业Load Balance方案,主要采用了DNS的域名轮换指向技术,即在DNS服务器上使来在用户浏览器的请求平均分配给不同的Web服务器。

这种属于单一的可扩展群集技术(Scalability-only Clustering),Web服务器群仅仅具有可扩展性,应付突发的高访问量。
例子有:
Round Robin DNS
F5 BigIP/LB
Other older HW solutions
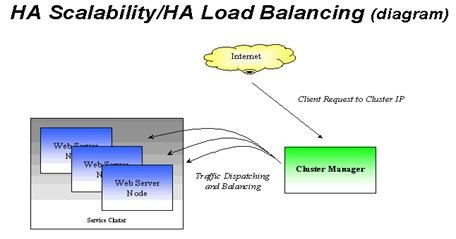
新的解决方案是高可用性可扩展技术/高可用性负载均衡技术(HAScalability/HA Load Balancing Clusters),加入了故障处理机制。
它同时提供可扩展性和高可靠性,一般用来提供核心网络服务:Web, mail, news, 等等。大的ISP和企业会用到,起价$25,000到$50,000之间,随着价格下降,更多用户会对此产生兴趣。采用这种方案的有:
Resonate Central Dispatch
F5 BigIP
Cisco LocalDirector
TurboCluster Server
Linux Virtual Server(Piranha, UltraMonkey等)
而这些方案中,最具价格优势的是TurboCluster 和Linux Virtual Server(LVS)。TurboCluster软件目前约20,000人民币,而LVS则加入了GPL公约,是免费的。
2.3 Scientific (Beowulf, MOSIX, PVM, MPI)
和刚才说的两种cluster的目的不同,这种cluster的主要目的是为了提高计算机处理任务的速度。应用程序需要被写成一种分布式应用程序,在运行时被分成分布式处理的进程,同时运行在多个节点上。例子:
Beowulf Cluster
Supercomputer Architectures
MPI(Message Passing Interface)
MOSIX
PVM(Parallel Virtual Mation)
2.4小节
从上面可以看出,Cluster并不是什么新的思想,Cluster思想已经发展多年,比较成熟。但原来都需要专业的软/硬件设备才能实现。所以只有少数公司才有能力用的起。但随的linux的流行,出现了许多基于linux,基于PC的cluster解决方案,使更多的人有机会构建自己的cluster。而且这些基于linux的软件大多都是遵循GPL协议的,是Open Source的。从而更推动了cluster技术的发展。
3. Heartbeat
3.1设计思想
Heartbeat顾名思义,就是心跳。两台计算机通过某种途径向对方发送“heartbeat”,同时也在监听对方的“heartbeat”。从而知道对方的状态。这种途径可以是串口线,也可以是网卡。可以同时使用。但如果只用一块网卡,则会发生单故障点SPOF[Single Point of Failure: a part which renders an entire system unusable when if fails (SPOF)]
Heartbeat除了在互相发送消息外,另外一项重要的工作就是接替和释放资源。比如:
假设系统主服务器为192.168.2.49,副服务器为192.168.2.47。平时主服务器虚拟192.168.2.48这个IP,当主服务器出问题时(比如关机),192.168.2.47自动虚拟192.168.2.48这个IP。
3.2 安装
Heartbeat属于应用程序级别的程序,所以不需要修改内核。只要取得其源代码。在任意目录下释放(/tmp),然后编译安装即可
tar xzvf heartbeat-0.4.6.tar.gz
cd heartbeat-0.4.6
make
make install
3.3 配置
Heartbeat的安装很容易,关键步骤是配置,第一个需要配置的文件为/etc/ha.d/ha.cf,具体配置选项在里面都有注释,下面是一个例子:
logfacility local0
keepalive 1
deadtime 3
serial /dev/ttyS0
nice_failback off
node tst_sd5_svr9
node tst_sd5_svr7
这里表示主节点为tst_sd5_svr9(192.168.2.49), 副节点为tst_sd5_svr7(192.168.2.47)
第二个需要配置的文件为/etc/ha.d/haresources,具体配置选项在里面都有注释,下面是一个例子:
tst_sd5_svr9 IPaddr::192.168.2.48/24 httpd
这个告诉系统主节点是tst_sd5_svr9,当heartbeat启动时,虚拟192.168.2.48这个IP。并且启动/etc/rc.d/init.d/httpd start这个命令。
第三个需要配置的文件是/etc/ha.d/authkeys,下面是一个例子:
auth 2
2 sha1 ultramonkey
注意,这个文件的属性一定要是600,所以要用chmod 600 authkeys设一下。然后就可以用/etc/rc.d/init.d/heartbeat start启动heartbeat服务了。还可以设为系统启动时自动启动:
cd /etc/rc.d/rc0.d ; ln -s ../init.d/heartbeat K01heartbeat
cd /etc/rc.d/rc3.d ; ln -s ../init.d/heartbeat S99heartbeat
cd /etc/rc.d/rc5.d ; ln -s ../init.d/heartbeat S99heartbeat
cd /etc/rc.d/rc6.d ; ln -s ../init.d/heartbeat K01heartbeat
至此,heartbeat就可以工作了,log文件在/var/log/ha-log中。
3.4 特点
前面基本已经说过,heartbeat能提供HA,但不能提供扩展性。也就是说cluster的性能就是一台server的性能。所以heartbeat一般都是和load balance结合起来使用。下面的load balance就是结合heartbeat的例子,因为单纯的load balance如果没有HA,则当负责分配任务的router(switcher)出问题时,整个cluster都会不工作。
4. Load-Balance
4.1设计思想
Load balance是通过router(switcher)把任务分派到真实节点上来提高整个cluster的性能,整个cluster的性能是由真实节点的性能和真实节点的数量决定的。所以,同一个cluster中的各个真实节点的内容都是一样的。是完全相同的镜象。当整个cluster的能力不够是,可以增加真实节点来提高性能。而增加真实节点只是在网络里增加几台计算机,所以不用关掉其他机器,只需在router上的真实节点表里增加几条记录就可以了。
4.2和传统方式的比较
有用其他方式实现类似功能的解决方案,比如前面提到的修改DNS,让一个域名对应多个IP,这样也可以把任务分派到多台机器上去。或者在路由器上把任务分给多台机器。第一做法是完全随机的,第二种做法是固定的,两者都不会根剧当时情况调整分配到真实节点上的任务量。而LVS提供了4中分配方法(Load-balancing Methods)和3种转发机制(Traffic Forward Mechanism)。具体情况在后面介绍
4.3 LVS
l 设计思想及特点
LVS提供了4种负载平衡的分配方法(Load-balancing Methods)和3种转发机制(Traffic Forward Mechanism)。
负载平衡方法: 名称
简介
Round robin
在实际服务器间平均分配负载
Leastconnections
最少活动连接数的服务器分配较多的负载 (The IPVS table stores active connections.)
Weighted round robin
根据动态负载权重和服务器的处理能力,在实际服务器中平均分配负载
Weighted leastconnections
根据服务器的权重,为最少连接数的服务器分配负载。
LVS提供了3种转发机制(Traffic Forward Mechanism)
分别为VS-NAT,VS-TUN 和VS-DR VS-NAT
VS-TUN
VS-DR
Server
any
tunneling
non-arp device
server network
private
LAN/WAN
LAN
server number
low (10~20)
high
High
server gateway
load balancer
own router
own router
3种转发机制中。常用的是VS-NAT。这种方式只需要几个公有IP,真实节点都在内部使用私有IP。而且真实节点可以是任何系统(包括NT),缺点是router(switcher)是整个系统的瓶颈,因为所有的数据都会通过router。一般真实节点数为20台左右。但这个问题可以解决,一种方法是混合途径,即设多个cluster组,然后通过DNS指向这几个router。另一种方法就是用VS-TUN或VS-DR
l 安装
所谓安装只需要在router上进行,真实节点不需要安装,特别是VS-NAT方式。这是节点唯一需要做的就是把设定一下缺省网关。安装LVS需要重新编译linux内核。在安装LVS时,需要下载相应版本的内核补丁。比如我们实验用的内核为2.2.14,相应补丁为ipvs-0.9.12-2.2.14.tar.gz
假设内核在/usr/src/linux中。ipvs-0.9.12-2.2.14.tar.gz被释放在/root/ipvs-0.9.12-2.2.14中。
1.先给内核做patch
cd /usr/src/linux
cat /root/ipvs-0.9.12-2.2.14/ipvs-0.9.12-2.2.14.patch | patch -p1
2.然后配置内核选项
make xconfig
Kernel Compile Options:
Code maturity level options ---
[*] Prompt for development and/or incomplete code/drivers
Networking options ---
[*] Network firewalls
....
[*] IP: firewalling
....
[*] IP: masquerading
....
[*] IP: masquerading virtual server support
(12) IP masquerading table size (the Nth power of 2)
IPVS: round-robin scheduling
IPVS: weighted round-robin scheduling
IPVS: least-connection scheduling
IPVS: weighted least-connection scheduling
....
[*] IP: aliasing support
其他选项根据需要选如网卡驱动程序
3.编译内核并用新内核启动
4.编译ipvsadm管理程序
cd /root/ipvs-0.9.12-2.2.14/ipvsadm
make install
重新启动系统就可以用ipvsadm来配置和管理cluster了
l 设置
具体设置方法在讲Piranha(水虎鱼)与Ultra Monkey文挡里有讲述。LVS的安装相对来说比较麻烦,但如果选用Piranha(这是RedHat公司基于LVS开发的产品,遵守GPL的),则只要正常安装RH6.1或RH6.2就免去了安装过程,而Ultra Monkey则提供了编译好的内核,而且是以rpm格式提供的,安装也非常简单。
5. MOSIX
5.1 Beowulf
一谈到并行计算,研究cluster的人第一个提到的就是Beowulf。Beowulf是目前最有名的基于廉价PC并行计算的cluster。但是Beowulf对硬件有特殊的要求。它需要千兆级速度的网卡,我们现在自己使用的网卡都是10M速度的。如果要研究Beowulf,需要在硬件上额外投资,这些时我们暂时所不能负担的,所以没有采用Beowulf方案
5.2 MOSIX是什么
MOSIX (The Multicomputer OS for UNIX)在底层实现了进程在处理器之间的迁移,对于用户和程序来说这种迁移的过程是透明的,用户不需要加以干涉(当然也能够干涉)。所有迁移过程都是根据一定的算法自动进行的,可以充分利用CPU和内存资源。尽管MOSIX在文挡重称自己进行负载均衡(load balance)运算,但它不同与其它的load balance(LVS,TurboCluster等),它不能处理象web server或ftp server这样的I/O紧张的程序,MOSIX做的还是超级计算(super computering)方面的工作。它可以同时使很多人在服务器上运行程序,作为一个多用户的分时环境(Multi-user, time sharing environment),也可以做科学计算(需要用并行通信机制PVM/MPI把程序预先编成可以并行计算的)
关于MOSIX更详细的介绍。在MOSIX网站上有一篇Slide Show “MOSIX Scalable Cluster Computing for Linux” 介绍得很详细。
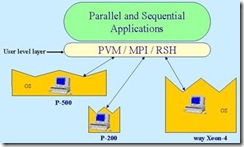
MOSIX提供了内核级的接口,相对于内核级接口的是用户级接口。下面是用户级接口的图示:
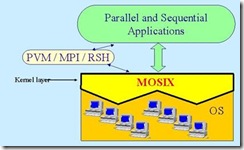
下面是内核级接口的图示
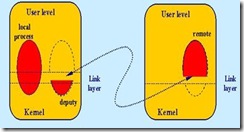
比较起来,内核级的优点是对用户来将是透明的。用户不必和各个节点打交道。在用户看来,所有的节点就象一台机器。在MOSIX上运行的进程被分为两部分:
而上面的部分可以在cluster节点中移动,根据当时节点的负载情况。所以,MOSIX可以更有效的使用各节点的CPU资源和内存资源。
5.3 MOSIX与PVM的关系
PVM是Parallel Virtual Machine的缩写。PVM实际上提供了一组API。用这种API,用户可以开发并行应用程序。并行应用程序在运行时会并发的产生多个进程同时执行。这些进程同时在多台机器上运行以缩短整个程序所需的运行时间。
PVM在不需要MOSIX的情况下可以正常执行。但在基于MOSIX的平台上运行PVM。会提高性能。PVM是用来写并行程序并运行,MOSIX是负责各个节点的资源调度。这就是PVM与MOSIX之间的关系
5.4安装MOSIX
MOSIX需要重新编译内核,使内核支持上面提到的进程迁移机制。所以,需要linux内核源代码以及MOSIX补丁。MOSIX提供了安装脚本,根据此安装脚本,用户可以很容易的完成安装过程(当然,在配置内核选项时,用户需要有基本的配置内核的知识)。
一、安装
1. 首先在/tmp下解开MOSIX软件包。
2. 运行安装脚本
cd /tmp
./mosix.install
这个安装脚本将指导下面的安装过程。
3.在配置内核时,有4项要选
CONFIG_MOSIX (YES)
CONFIG_BINFMT_ELF (YES)
CONFIG_PROC_FS (YES)
CONFIG_KMOD (YES)
4.整个安装过程结束,重起系统,就可以配置系统了,MOSIX的自动安装过程中完成了配置过程,它在安装过程中修改了以下文件:
/etc/inittab
/etc/inetd.conf
/etc/lilo.conf
/etc/rc.d/init.d/atd
/etc/cron.daily/slocate.cron
二.节点配置
节点配置是通过修改/etc/mosix.map这个文件来实现的。示例配置文件如下(不跨网段):
# MOSIX CONFIGURATION
# ===================
#
# Each line should contain 3 fields, mapping IP addresses to MOSIX node-numbers:
# 1) first MOSIX node-number in range.
# 2) IP address of the above node (or node-name from /etc/hosts).
# 3) number of nodes in this range.
#
# MOSIX-# IP number-of-nodes
# ============================
1 192.168.2.42 1
2 192.168.2.47 1
3 192.168.2.49 1
#或空格开头的是注释。每行配置有3个栏位
1. MOSIX节点号
2. IP地址(必须在/etc/hosts里指定IP-hostname的对应关系)
3. 节点数目
刚才是IP都不连续的的情况,所以节点数目都是1,假如我们有192.168.2.100-192.168.2.200这100台节点,则可以写成
1 192.168.2.100 100
更复杂的配置方法可以参照man mosix。与mosix.map相关的文件有/etc/hosts、/etc/mospe和/etc/mosgates (后两个文件都是在跨网段时会用到,我们目前的配置中不需要)
关于MOSIX的管理,MOSIX基本上不需要人为干涉,但如果用户希望干涉进程的运行状况,MOSIX提供了一套管理程序。MOSIX的管理主要是通过对/proc/mosix/下的文件进行操作来完成的。
5.5安装PVM
PVM的安装不需要修改内核,它只需要普通用户的权限就可以安装。比如用户cluster在3台机器上都有用户,则可以利用这三台机器的资源进行并行计算。安装工作需要在用户的主目录$HOME下进行。经过解包,生成$HOME/pvm3目录;设置一些环境变量;编译,安装就完成了。在PVM设置好以后,就可以用pvm命令进入pvm虚拟机环境。在上面可以运行并行应用程序。也可以不进入虚拟机环境,直接在命令行上提交任务。这些只是PVM的运行环境,PVM的另一部分是其提供的开发环境。在pvm里有c和fortran语言的接口,用户使用这些接口(Interface)用c语言或fortran语言就可以写出并行应用程序然后在pvm运行环境上运行。在其主页上还看到其他的一些语言接口,比如
java,perl,c++
PVM有NT版和UNIX版,由于PVM有虚拟机的概念,所以协同工作的节点可以是NT,linux和其他系统的混合构架,之间只要通过tcp/ip协议连接就可以。(但MOSIX没有NT版的)
6. 结论
以上对服务器群集技术(Server Cluster)做出了简单的介绍。现在正在进行的cluster的项目很多(有遵守GPL公约的,也有商业化的),这些只是cluster中的一小部分。不过这些Cluster方式基本上都是我们目前实际具有的软硬件情况所能够实现的技术。这些技术即具有各自的应用价值,分别适用于Cluster的三个方面,又有各自的不足之处。从这些技术的思路出发,借助自由软件的免费及技术公开的优势,开发出自己的Cluster系统是完全可行的。
本文来自CSDN博客,转载请标明出处:http://blog.csdn.net/Mr_JBean/archive/2008/10/08/3033128.aspx